


What is availability?
Availability is a way to measure the durability of a system. Availability can be defined as the length of time a system is actually functioning (or service operational), divided by the length of time the system could have been working.
What are typical availability levels?
 Systems are usually segmented into availability levels by their number of “nines,” and further described using terms like “highly-available” and “fault-tolerant.” If a system is available 99% of the time (two nines), that then means it’s not available 1% of the time. In any given year with 525,600 available minutes, you can expect a “two nines” system to be down for 5256 of those minutes, or for about 88 hours or 4 days. Depending on your particular cost of downtime, this can be expensive.
Systems are usually segmented into availability levels by their number of “nines,” and further described using terms like “highly-available” and “fault-tolerant.” If a system is available 99% of the time (two nines), that then means it’s not available 1% of the time. In any given year with 525,600 available minutes, you can expect a “two nines” system to be down for 5256 of those minutes, or for about 88 hours or 4 days. Depending on your particular cost of downtime, this can be expensive.
| Availability | Number of nines | Downtime per year | Often described as |
|---|---|---|---|
| 99.9% | Three nines | 526 minutes or less | Available |
| 99.99% | Four nines | 53 minutes or less | Highly-available |
| 99.999% | Five nines | 5 minutes or less | Fault-tolerant |
Systems operating at higher “four nines” and “five nines” average availability levels are often called “highly-available” or “fault-tolerant” systems.
What are common methods used to increase availability?
There are several time-tested methods companies use to improve availability, ranging from improving system reliability and resilience, implementing backup and recovery procedures, or deploying redundant clusters (physical or virtual) with failover services.

Rugged, fan-less, IP-40 rated
Using reliable and resilient systems
One way to improve availability is to use more reliable systems. The more rugged and reliable your system, the less likely it is to break down. The less it breaks down, the longer it keeps running, and by definition, the longer it’s available.
A related way to increase availability is to implement a more resilient system – one that can bounce back quickly from a setback. By reducing the time it takes to repair the system and resume services, you are lowering downtime and increasing overall availability. What’s interesting is that if a system can bounce back quickly every time, then it matters less how often it breaks.
Implementing backup and recovery
Reliability and resilience have their limits though. In many cases, it’s not just system availability, but data protection and data integrity that you also have to worry about.
Companies taking a more holistic approach to availability will often backup their data on a regular basis and keep spare systems in inventory. If their production systems experience a catastrophic failure, they restart services on their spare systems, recovering the data they need from their archives.
Setting up backup and recovery services requires some skill. And the time to recover can vary, from a few hours to a few days, depending on the applications, the amount of data, and the availability of spare parts.
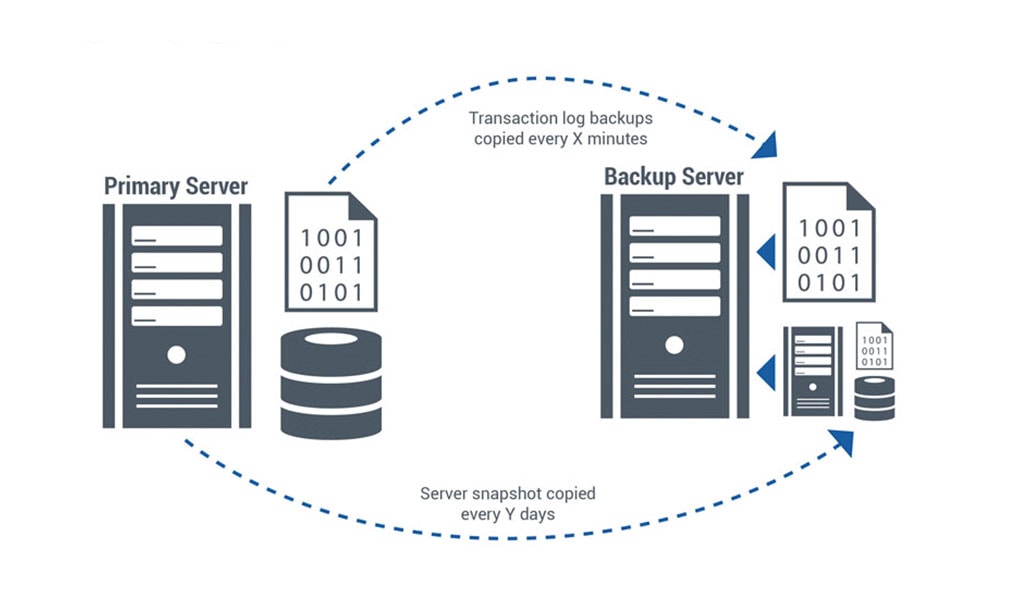
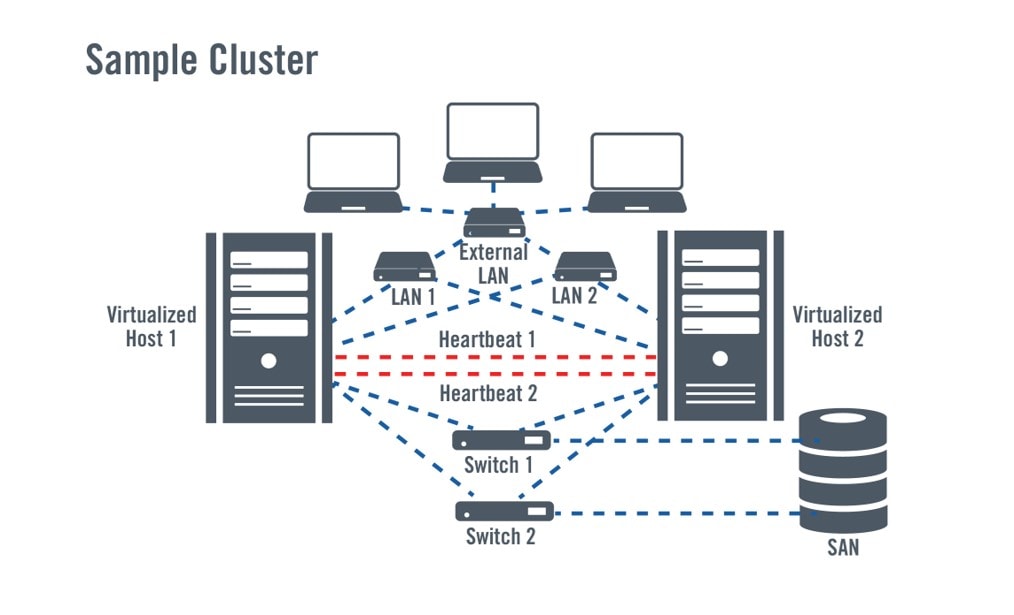
Using native and virtual clustering and failover services
For some companies, resuming services after a few hours or a few days may be acceptable. But those with higher relative downtime costs need a more resilient approach, for both their applications and data.
Clustering and failover uses the same principle as backup and recovery, but shortens the time to recover services by doing some things in advance, like replicating systems so that they’re ready to resume at a moment’s notice. Several systems are combined and data is shared by these redundant systems. Typically, one system acts as the primary, providing users with access to applications and data, while a secondary system acts as a backup, either staying dormant until needed (passive) or running other applications (active). In the event of a failure to the primary system, the application will “failover” to the secondary system and resume running there, so long as the connections to shared data are established.
With the emergence of virtualization technologies, clustering and failover concepts have been extended to virtual systems. Today, virtualization and clustering technologies are being used to combine physical systems and failover applications running on virtual machines (VM), taking advantage of VM portability.
What does Stratus offer?
Stratus offers a wide variety of edge computing solutions covering the full availability spectrum. From software only products like everRun, to complete solutions like ztC Edge and ftServer that include hardware, software, and services, Stratus helps customers easily and affordably deliver highly-available and fault-tolerant workloads.