Che cos'è la disponibilità?
La disponibilità è un modo per misurare la durata di un sistema. La disponibilità può essere definita come il periodo di tempo in cui un sistema è effettivamente funzionante (o servizio operativo), diviso per il tempo in cui il sistema avrebbe potuto funzionare.
Quali sono i livelli di disponibilità tipici?
 I sistemi sono di solito segmentati in livelli di disponibilità per il loro numero di "nove", e ulteriormente descritti usando termini come "altamente disponibile" e "tollerante ai guasti.” Se un sistema è disponibile per il 99% del tempo (due nove), significa che non è disponibile per l'1% del tempo. In un anno con 525.600 minuti disponibili, ci si può aspettare che un sistema "due nove" sia inattivo per 5256 di quei minuti, o per circa 88 ore o 4 giorni. A seconda del vostro particolare costo dei tempi di inattivitàQuesto può essere costoso.
I sistemi sono di solito segmentati in livelli di disponibilità per il loro numero di "nove", e ulteriormente descritti usando termini come "altamente disponibile" e "tollerante ai guasti.” Se un sistema è disponibile per il 99% del tempo (due nove), significa che non è disponibile per l'1% del tempo. In un anno con 525.600 minuti disponibili, ci si può aspettare che un sistema "due nove" sia inattivo per 5256 di quei minuti, o per circa 88 ore o 4 giorni. A seconda del vostro particolare costo dei tempi di inattivitàQuesto può essere costoso.
| Disponibilità | Numero di nove | Tempi di inattività all'anno | Spesso descritto come |
|---|---|---|---|
| 99.9% | Tre nove | 526 minuti o meno | Disponibile |
| 99.99% | Quattro nove | 53 minuti o meno | Altamente disponibile |
| 99.999% | Cinque nove | 5 minuti o meno | Fault-tolerant |
I sistemi che operano a livelli di disponibilità media superiori a "quattro nove" e "cinque nove" sono spesso chiamati sistemi "altamente disponibili" o "a prova di guasto".
Quali sono i metodi comuni utilizzati per aumentare la disponibilità?
Esistono diversi metodi collaudati nel tempo che le aziende utilizzano per migliorare la disponibilità, che vanno dal miglioramento dell'affidabilità e della resilienza del sistema, all'implementazione di procedure di backup e ripristino, all'implementazione di cluster ridondanti (fisici o virtuali) con servizi di failover.

Robusto, senza ventola, con grado di protezione IP-40
Utilizzo di sistemi affidabili e resilienti
Un modo per migliorare la disponibilità è quello di utilizzare sistemi più affidabili. Più il sistema è robusto e affidabile, meno probabilità ha di rompersi. Meno si rompe, più a lungo continua a funzionare e, per definizione, più a lungo è disponibile.
Un modo correlato per aumentare la disponibilità è quello di implementare un sistema più resiliente - un sistema che possa rimbalzare rapidamente da una battuta d'arresto. Riducendo il tempo necessario per riparare il sistema e riprendere i servizi, si riducono i tempi di fermo macchina e si aumenta la disponibilità complessiva. La cosa interessante è che se un sistema può rimbalzare velocemente ogni volta, allora conta meno la frequenza delle interruzioni.
Implementazione di backup e ripristino
Affidabilità e resilienza hanno però i loro limiti. In molti casi, non è solo la disponibilità del sistema, ma anche la protezione dei dati e l'integrità dei dati a doversi preoccupare.
Le aziende che adottano un approccio più olistico alla disponibilità spesso eseguono regolarmente il backup dei loro dati e tengono i sistemi di riserva in magazzino. Se i loro sistemi di produzione subiscono un guasto catastrofico, riavviano i servizi sui loro sistemi di riserva, recuperando i dati di cui hanno bisogno dai loro archivi.
L'impostazione dei servizi di backup e ripristino richiede una certa abilità. E i tempi di ripristino possono variare, da poche ore a qualche giorno, a seconda delle applicazioni, della quantità di dati e della disponibilità di ricambi.
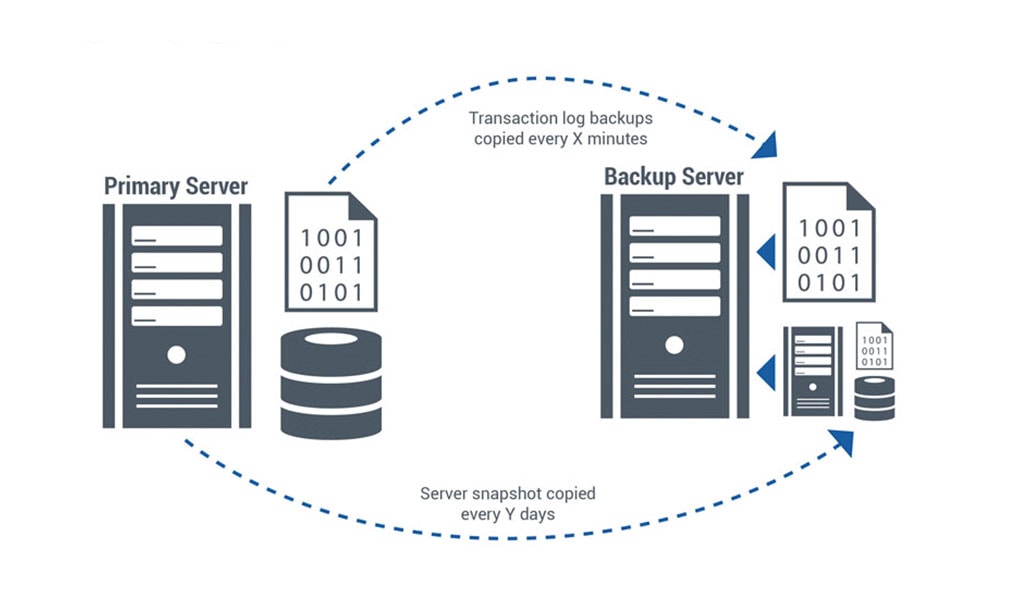
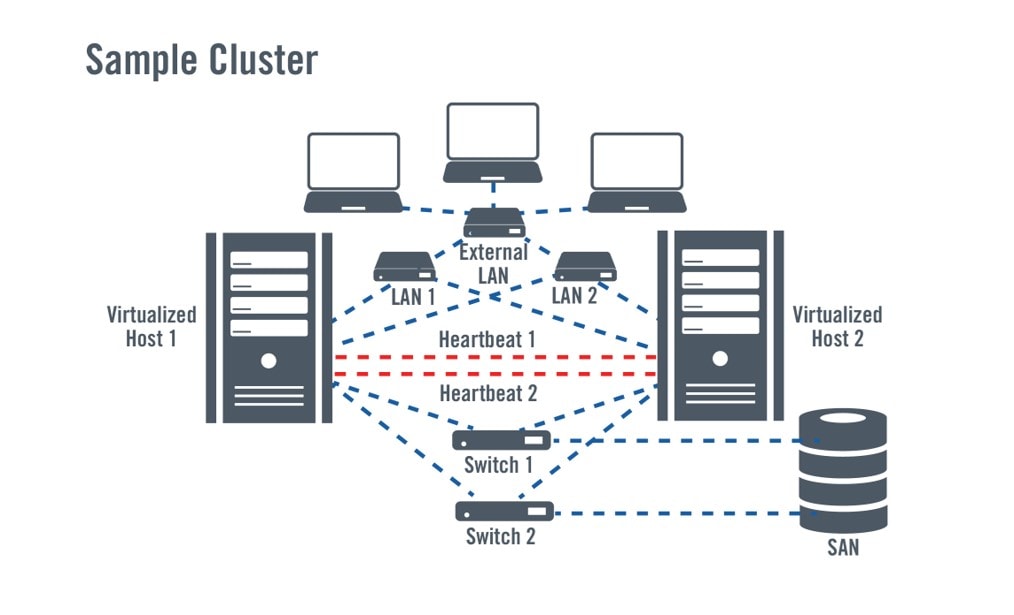
Utilizzo di servizi di clustering e failover nativi e virtuali
Per alcune aziende, la ripresa dei servizi dopo poche ore o qualche giorno può essere accettabile. Ma quelle con costi di fermo macchina relativi più elevati necessitano di un approccio più resiliente, sia per le loro applicazioni che per i dati.
Il clustering e il failover utilizzano lo stesso principio del backup e del ripristino, ma accorciano i tempi di ripristino dei servizi facendo alcune cose in anticipo, come la replica dei sistemi in modo che siano pronti a riprendere in un attimo. Diversi sistemi sono combinati e i dati sono condivisi da questi sistemi ridondanti. In genere, un sistema funge da sistema primario, fornendo agli utenti l'accesso alle applicazioni e ai dati, mentre un sistema secondario funge da backup, rimanendo inattivo fino al momento del bisogno (passivo) o eseguendo altre applicazioni (attivo). In caso di guasto al sistema primario, l'applicazione si "failover" verso il sistema secondario e riprende a funzionare in esso, a condizione che vengano stabilite le connessioni ai dati condivisi.
Con l'emergere delle tecnologie di virtualizzazione, i concetti di clustering e failover sono stati estesi ai sistemi virtuali. Oggi, le tecnologie di virtualizzazione e di clustering vengono utilizzate per combinare sistemi fisici e applicazioni di failover che girano su macchine virtuali (VM), sfruttando la portabilità delle VM.
Cosa offre Stratus ?
Stratus offre un'ampia varietà di edge computing soluzioni che coprono l'intero spettro della disponibilità. Dai prodotti solo software come everRuna soluzioni complete come ztC Edge e ftServer che includono hardware, software e servizi, Stratus aiuta i clienti a fornire facilmente ed economicamente carichi di lavoro altamente disponibili e tolleranti ai guasti.