Cos'è la tolleranza alla colpa?
La tolleranza ai guasti descrive un livello superiore di disponibilità caratterizzato da 5 nove uptime (99,999%) o superiore. I sistemi con tolleranza ai guasti sono in grado di fornire questi livelli di disponibilità, perché possono "tollerare" o sopportare sia i "guasti" hardware che software o i guasti. Di solito lo fanno sia monitorando e prevenendo in modo proattivo e prevenendo i guasti dei sistemi critici in primo luogo, sia attenuando completamente il rischio di un componente o di un guasto catastrofico del sistema.
Tolleranza ai guasti basata sul software rispetto all'hardware
La tolleranza ai guasti può essere ottenuta utilizzando sia approcci basati su software che su hardware.
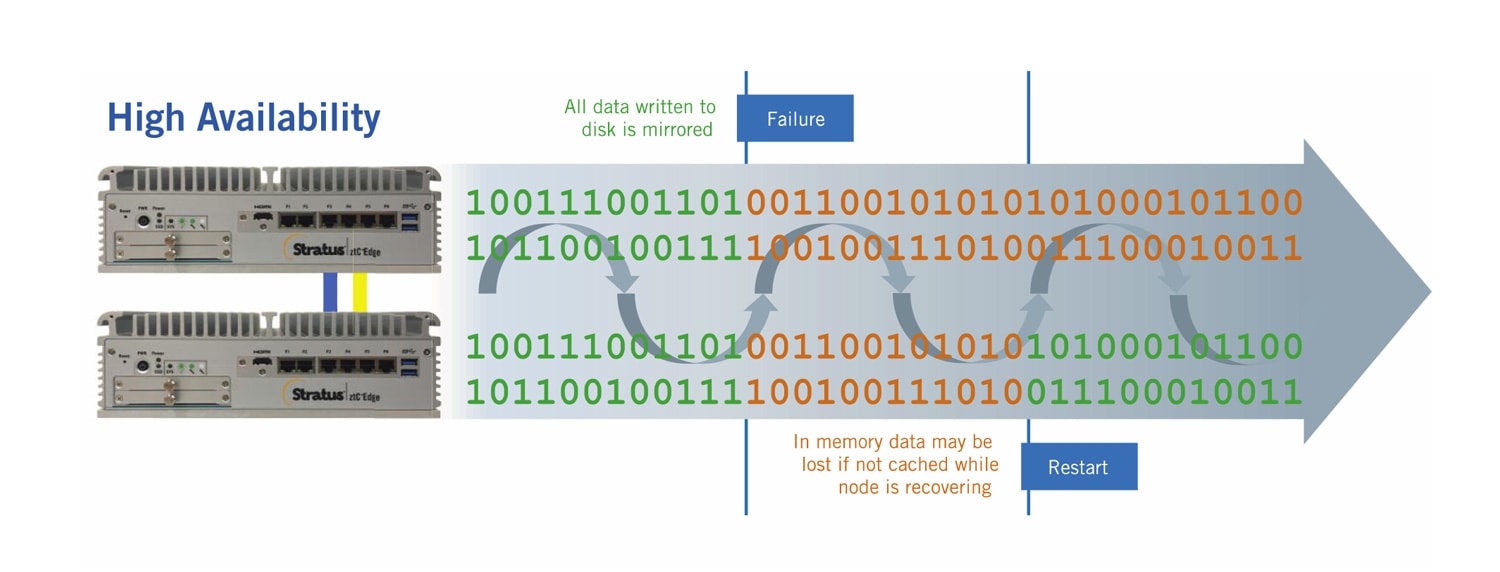
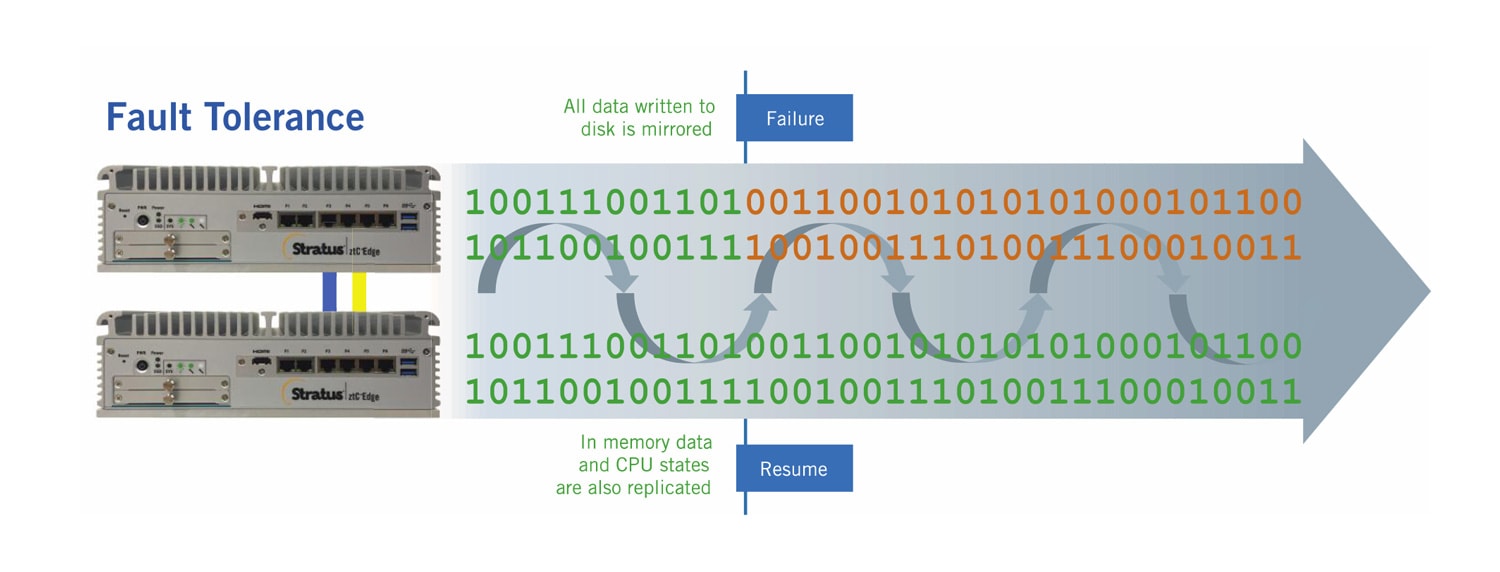
In un approccio basato sul software, tutti i dati impegnati su disco sono specchiati su sistemi ridondanti. Approcci più sofisticati basati su software replicano anche i dati non impegnati, o i dati in memoria, in un sistema ridondante. In caso di guasto del sistema primario, un sistema di backup secondario riprende a funzionare, prendendo il controllo dal momento esatto in cui il sistema primario si guasta, in modo che nessuna transazione o dato venga duplicato o perso.
In un approccio basato sull'hardware, i sistemi ridondanti funzionano contemporaneamente. I server paralleli svolgono compiti identici, in modo che se un server fallisce, l'altro server continua a elaborare le transazioni o a fornire servizi. Questo approccio si basa sul fatto che la probabilità statistica che entrambi i sistemi falliscano contemporaneamente è estremamente bassa. In realtà è necessario un solo server per fornire le applicazioni, ma avere due server aiuta a garantire che almeno uno di essi sia sempre in funzione.
Come everRun® Enterprise e ztC™ Edge forniscono carichi di lavoro fault-tolerant
Stratus everRun Il software aziendale e le Stratus ztC Edge Le piattaforme di calcolo utilizzano entrambi approcci basati sul software per fornire applicazioni tolleranti agli errori e proteggere i dati.
La sfida principale con gli approcci basati sul software consiste nel replicare i dati in modo efficiente, riducendo al minimo le spese generali del sistema. Non replicare abbastanza e i tempi di recupero aumentano. Replicate troppo spesso e utilizzate troppe risorse di sistema solo per garantire la disponibilità.
everRun Enterprise e Stratus Redundant Linux, la piattaforma operativa che alimenta Stratus' ztC Edge soluzione, replicano tutti i dati scritti su disco (per carichi di lavoro altamente disponibili) e utilizzano un motore di checkpointing unico per replicare continuamente i dati in memoria e gli stati della CPU (per carichi di lavoro fault tolerant). Tutte le operazioni di I/O sono accodate fino a quando i checkpoint sono completati e verificati. Gli algoritmi proprietari regolano dinamicamente la frequenza di checkpointing, in base al tipo e alla quantità di modifiche ai dati e al throughput I/O. Se/quando un nodo fallisce, viene usata una pausa di due secondi per prevenire scenari di split brain, risultando in un tempo di recupero inferiore ai cinque secondi - sotto la soglia TCP/IP per l'accodamento e la ripresentazione delle richieste.
Oltre al suo motore di controllo unico e altamente efficiente, le soluzioni Stratus si distinguono per la loro semplicità operativa. Non sono necessarie modifiche alle applicazioni o al sistema operativo guest per renderle consapevoli del cluster. Non sono necessari ulteriori script di failover per garantire la disponibilità delle applicazioni e l'integrità dei dati. Tutto ciò che serve è che le applicazioni siano installate in una macchina virtuale e lanciate per renderle tolleranti ai guasti.

Come ftServer® fornisce carichi di lavoro con tolleranza ai guasti
Stratus ftServer utilizza un approccio basato sull'hardware per fornire applicazioni e dati con tolleranza ai guasti.
La sfida principale con gli approcci basati sull'hardware è garantire la sincronizzazione precisa dei processi e dei thread - facendo in modo che le stesse cose accadano esattamente nello stesso momento su entrambi i nodi di un sistema ridondante.
Stratus ftServer utilizza array di gate programmabili in campo proprietario (FPGA) per garantire l'elaborazione dei lock-step su due metà identiche di un sistema ftServer . Le due unità sostituibili dal cliente identiche (CRU) funzionano in parallelo. Ciascuna di esse funge da server primario o secondario a seconda delle necessità. Ciascuna di esse esegue lo stesso processo nello stesso momento. Con ftServer, non c'è tempo di ripristino quando c'è un guasto in un singolo componente o in una CRU. La CRU disponibile assume semplicemente il ruolo di server primario fino alla sostituzione della CRU non disponibile. Per le organizzazioni che non possono tollerare nemmeno un secondo di fermo macchina non pianificato, Stratus ftServer è una valida opzione.
Oltre all'uso di FPGA e all'approccio lock-step, Stratus ftServer si distingue per la sua semplicità operativa. Le applicazioni, le piattaforme di virtualizzazione o i sistemi operativi guest che sono installati in ftServer non richiedono particolari modifiche o configurazioni per renderli tolleranti ai guasti.