


什么是容错?
容错性是指以5.9个正常运行时间(99.999%)或更高为特征的卓越的可用性水平。容错系统能够提供这些级别的可用性,因为它们能够"容忍"或承受硬件和软件"故障"或故障。 它们通常是通过主动监控和防止关键系统发生故障,或者通过完全降低灾难性组件或系统故障的风险来实现的。
基于软件的容错与基于硬件的容错
可采用基于软件和基于硬件的方法实现容错。
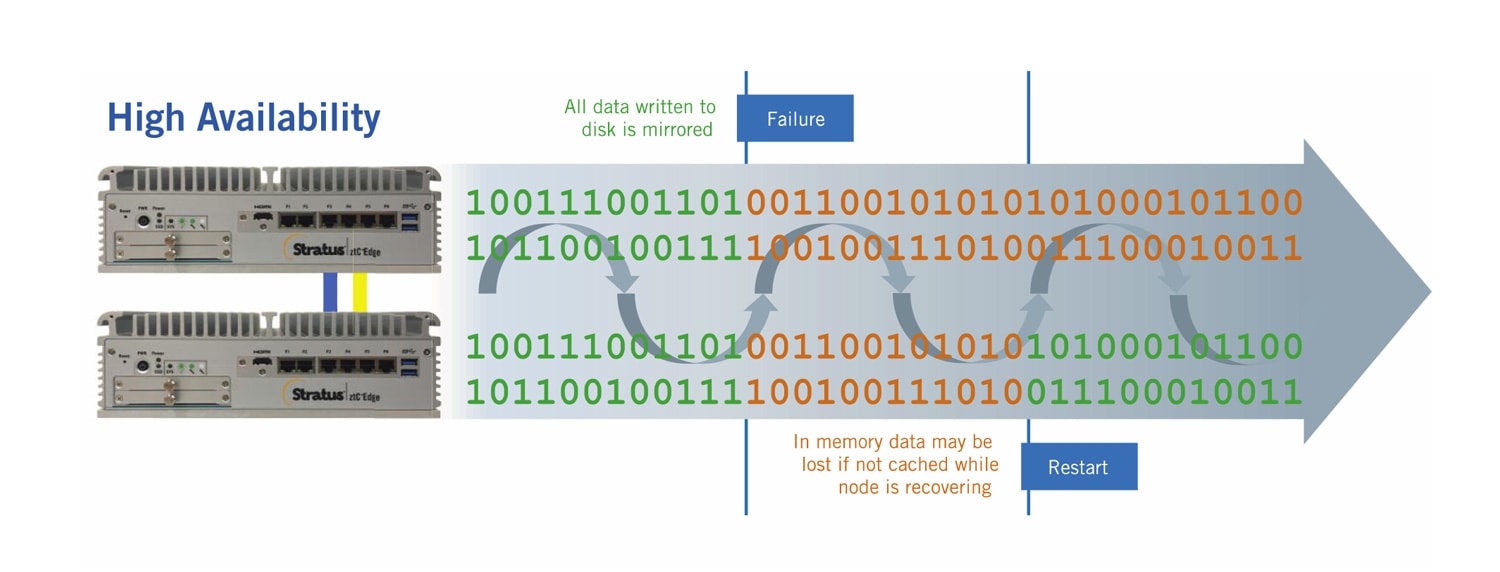
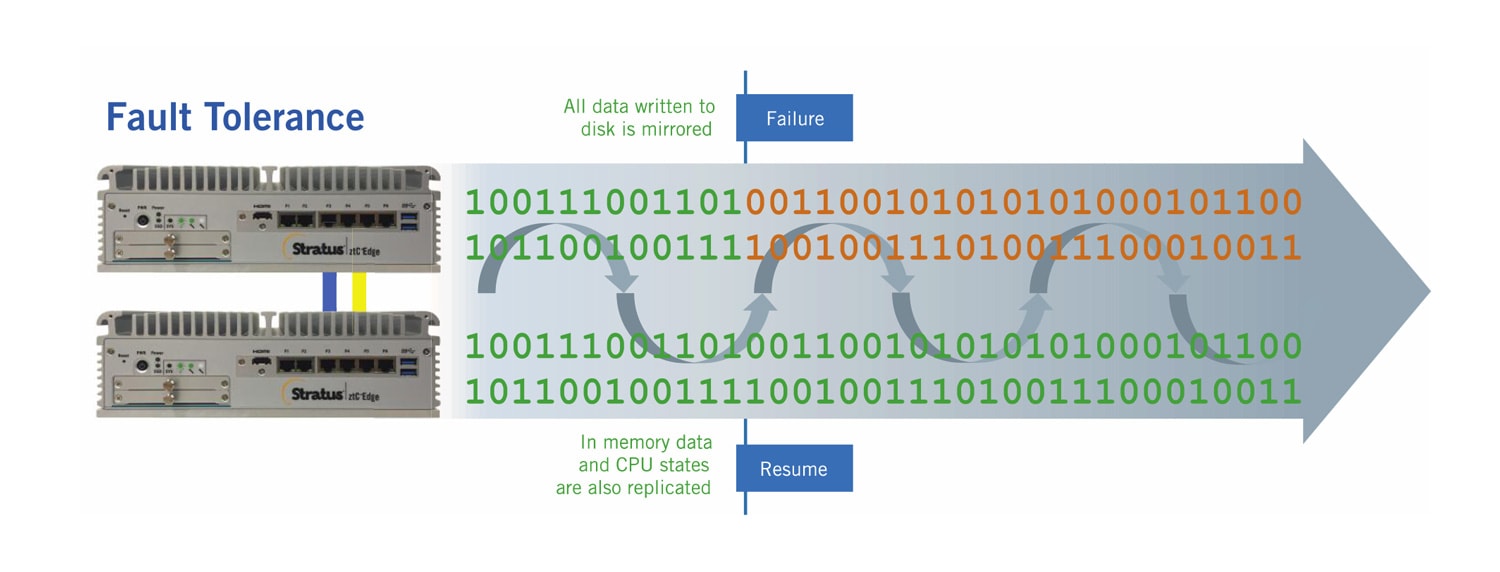
在基于软件的方法中,所有承诺在磁盘上的数据都在冗余系统中镜像。更复杂的基于软件的方法还将未承诺的数据或内存中的数据复制到冗余系统中。在主系统发生故障时,二级备份系统恢复运行,在主系统发生故障时接替主系统,这样就不会有任何事务或数据被重复或丢失。
在基于硬件的方法中,冗余系统同时运行。并行服务器执行相同的任务,因此,如果一台服务器发生故障,另一台服务器继续处理交易或提供服务。这种方法依赖于两个系统同时发生故障的统计概率极低。实际上只需要一台服务器来提供应用程序,但拥有两台服务器有助于确保至少有一台服务器始终在运行。
everRun® Enterprise 和 ztC™边缘 如何提供容错的工作负载
Stratus everRun企业软件和Stratus ztC 边缘计算平台都使用基于软件的方法来提供容错的应用程序和保护数据。
基于软件的方法的主要挑战是有效复制数据,同时将系统开销降到最低。如果复制的次数不够,你的恢复时间就会增加。太频繁地复制,你就会为了确保可用性而使用过多的系统资源。
everRun Enterprise和Stratus Redundant Linux,是支持Stratus' 的操作平台。 ztC 边缘 解决方案,复制所有写入磁盘的数据(用于高可用工作负载),并使用独特的检查点引擎持续复制内存和CPU状态的数据(用于容错工作负载)。所有的I/O操作都是排队的,直到检查点完成并被验证。根据数据变化的类型和数量以及I/O吞吐量,专有的算法动态调整检查点的频率。如果/当一个节点发生故障时,会使用两秒钟的暂停,以防止大脑分裂的情况发生,从而使恢复时间低于5秒--低于TCP/IP排队和重新提交请求的阈值。
除了独特、高效的检查点引擎,Stratus 解决方案还因其操作简单而与众不同。无需修改应用程序或客户操作系统即可使其具有集群感知能力。不需要额外的故障转移脚本来确保应用程序的可用性和数据完整性。所需要的只是将应用程序安装在虚拟机中并启动,使其具有容错性。

ftServer®如何提供容错工作负载?
Stratus ftServer使用基于硬件的方法来提供容错的应用和数据。
基于硬件的方法的主要挑战是确保进程和线程的精确同步--确保冗余系统的两个节点上在完全相同的时间发生完全相同的事情。
Stratus ftServer 采用专有的现场可编程门阵列(FPGA),确保在一个ftServer 系统的两个相同的半部分进行锁步处理。两个相同的客户可更换单元(CRU)并行运行。根据需要,每个单元都可以作为主服务器或辅助服务器。每个单元在同一时间执行相同的进程。使用ftServer ,当单个组件或CRU出现故障时,没有恢复时间。在不可用的CRU被替换之前,可用的CRU只需接替主服务器。对于不能容忍哪怕是一秒钟的计划外停机的组织来说,Stratus ftServer 是一个可行的选择。
除了使用FPGA和锁步方式外,Stratus ,ftServer ,其区别在于操作简单。安装在ftServer 中的应用程序、虚拟化平台或客体操作系统不需要进行特殊的修改或配置就可以使其具有容错性。