O que é disponibilidade?
A disponibilidade é uma forma de medir a durabilidade de um sistema. A disponibilidade pode ser definida como o período de tempo que um sistema está realmente funcionando (ou serviço operacional), dividido pelo tempo que o sistema poderia estar funcionando.
Quais são os níveis típicos de disponibilidade?
 Os sistemas são geralmente segmentados em níveis de disponibilidade por seu número de "noves", e descritos mais detalhadamente usando termos como "altamente disponível" e "tolerante a falhas.” Se um sistema estiver disponível 99% do tempo (dois noves), isso significa que ele não está disponível 1% do tempo. Em qualquer ano com 525.600 minutos disponíveis, você pode esperar que um sistema de "dois noves" fique fora do ar por 5256 desses minutos, ou por cerca de 88 horas ou 4 dias. Dependendo de sua particular custo do tempo de inatividadeIsto pode ser caro.
Os sistemas são geralmente segmentados em níveis de disponibilidade por seu número de "noves", e descritos mais detalhadamente usando termos como "altamente disponível" e "tolerante a falhas.” Se um sistema estiver disponível 99% do tempo (dois noves), isso significa que ele não está disponível 1% do tempo. Em qualquer ano com 525.600 minutos disponíveis, você pode esperar que um sistema de "dois noves" fique fora do ar por 5256 desses minutos, ou por cerca de 88 horas ou 4 dias. Dependendo de sua particular custo do tempo de inatividadeIsto pode ser caro.
| Disponibilidade | Número de noves | Tempo de inatividade por ano | Muitas vezes descrito como |
|---|---|---|---|
| 99.9% | Três noves | 526 minutos ou menos | Disponível em |
| 99.99% | Quatro noves | 53 minutos ou menos | Altamente disponível |
| 99.999% | Cinco noves | 5 minutos ou menos | Tolerante a falhas |
Os sistemas que operam com níveis médios de disponibilidade mais altos de "quatro noves" e "cinco noves" são freqüentemente chamados de sistemas "altamente disponíveis" ou "tolerantes a falhas".
Quais são os métodos comuns usados para aumentar a disponibilidade?
Há vários métodos testados pelo tempo que as empresas utilizam para melhorar a disponibilidade, desde a melhoria da confiabilidade e resiliência do sistema, a implementação de procedimentos de backup e recuperação, ou a implantação de clusters redundantes (físicos ou virtuais) com serviços de failover.

Resistente, sem ventilador, com classificação IP-40
Usando sistemas confiáveis e resilientes
Uma maneira de melhorar a disponibilidade é usar sistemas mais confiáveis. Quanto mais robusto e confiável for seu sistema, menor é a probabilidade de que ele se decomponha. Quanto menos ele se avariar, mais tempo ele continuará funcionando e, por definição, mais tempo ele estará disponível.
Uma maneira relacionada de aumentar a disponibilidade é implementar um sistema mais resistente - um sistema que possa se recuperar rapidamente de um contratempo. Ao reduzir o tempo necessário para reparar o sistema e retomar os serviços, você está diminuindo o tempo de inatividade e aumentando a disponibilidade geral. O que é interessante é que se um sistema pode recuperar rapidamente a cada vez, então importa menos a freqüência com que ele se rompe.
Implementação de backup e recuperação
Mas a confiabilidade e a resiliência têm seus limites. Em muitos casos, não é apenas a disponibilidade do sistema, mas também a proteção e a integridade dos dados que você tem que se preocupar.
As empresas que adotam uma abordagem mais holística em relação à disponibilidade freqüentemente fazem backup de seus dados regularmente e mantêm sistemas de reserva em estoque. Se seus sistemas de produção apresentarem uma falha catastrófica, eles reiniciam os serviços em seus sistemas sobressalentes, recuperando os dados necessários de seus arquivos.
A criação de serviços de backup e recuperação requer alguma habilidade. E o tempo de recuperação pode variar, de algumas horas a alguns dias, dependendo das aplicações, da quantidade de dados e da disponibilidade de peças de reposição.
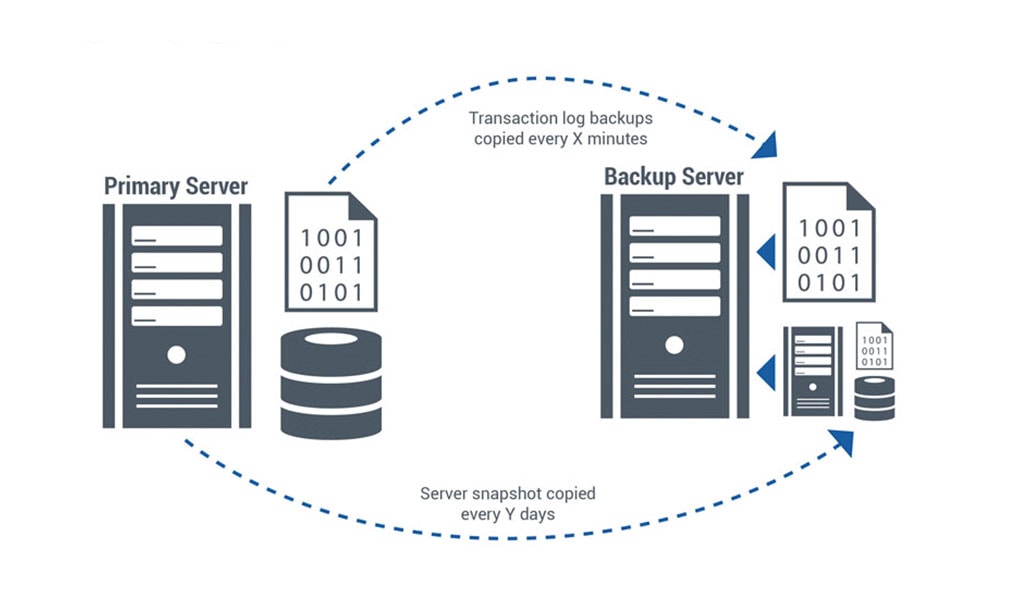
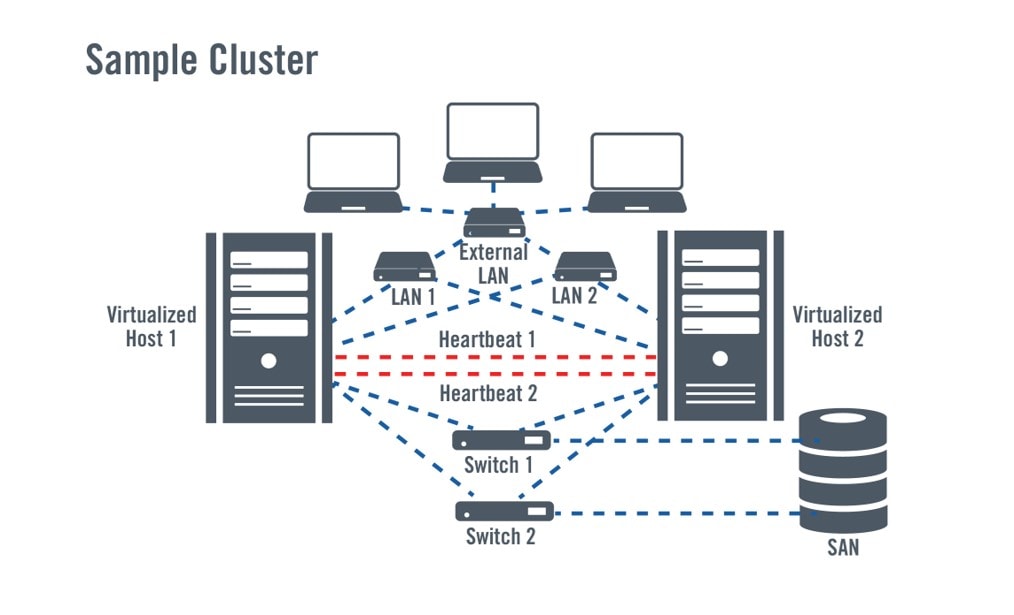
Usando serviços nativos e virtuais de clustering e failover
Para algumas empresas, a retomada dos serviços após algumas horas ou alguns dias pode ser aceitável. Mas aquelas com custos relativos de inatividade mais altos precisam de uma abordagem mais resiliente, tanto para suas aplicações quanto para os dados.
O agrupamento e o failover utilizam o mesmo princípio de backup e recuperação, mas encurta o tempo para recuperar serviços fazendo algumas coisas com antecedência, como replicar sistemas para que eles estejam prontos para retomar em um instante. Vários sistemas são combinados e os dados são compartilhados por estes sistemas redundantes. Normalmente, um sistema atua como o principal, fornecendo aos usuários acesso a aplicações e dados, enquanto um sistema secundário atua como backup, seja permanecendo inativo até que seja necessário (passivo) ou rodando outras aplicações (ativo). No caso de uma falha no sistema primário, a aplicação "falhará" no sistema secundário e voltará a funcionar lá, desde que as conexões aos dados compartilhados sejam estabelecidas.
Com o surgimento das tecnologias de virtualização, os conceitos de clustering e failover foram estendidos aos sistemas virtuais. Hoje, as tecnologias de virtualização e clustering estão sendo utilizadas para combinar sistemas físicos e aplicações de failover rodando em máquinas virtuais (VM), aproveitando a portabilidade da VM.
O que a Stratus oferece?
A Stratus oferece uma grande variedade de soluções informáticas edge cobrindo todo o espectro de disponibilidade. Desde produtos de software como EverRun, até soluções completas como ztC Edge e ftServer que incluem hardware, software e serviços, a Stratus ajuda os clientes a entregar cargas de trabalho altamente disponíveis e tolerantes a falhas de forma fácil e acessível.